今回紹介するのは入力画像の特定条件にあるピクセルにのみ指定パターンを表示する方法です。
[Tile Sampler] ノードにはランダムに配置したパターンがグレースケールの白の部分にのみ表示されるようにする機能があります。
この記事ではその簡易バージョンを作る方法を提示します。
簡易バージョンなのでもう少しちゃんと作らないと実用的にはならないのですが、仕組みがわかっていれば [Tile Sampler] ノードから該当部分を抜き出すこともできるようになるんじゃないでしょうか?
まだ自分はできていませんが、そのうちやる予定。
この処理には [FX-Map] を使用します。
このノードはSDでは唯一ループ処理を行うことが出来るノードであり、今回のようにパターンを複数回散りばめるのには大変便利です。
特定パターンを複数表示するノードとしては先に紹介した [Tile Sampler] も含まれるタイル系やスプラッタ系がありますが、これらは内部で [FX-Map] を使用しています。
まずは準備をしましょう。以下のようにノードを作成します。

[Image Input 0] に入力された円が今回は散りばめるパターン、[Image Input 1]に入力された三角が表示位置を示す画像とします。
[FX-Map] ノードの [Color Mode] はグレースケールに変更しておきましょう。
次に入力パラメータを追加しておきます。以下のように作成します。

[tile_num_x/y] はXY座標のタイルの数で、この数値分画像が分割されます。
[gray_threshold] は [Image Input 1] の該当ピクセルがこの値以上の場合にパターンを表示するようにするためのしきい値です。
では、[FX-Map] を選択し、[Ctrl + E] で内部に入っていきましょう。
内部は以下のようにします。
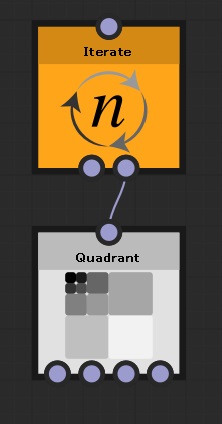
最初から入っている [Quadrant] ノードの上に [Iterate] ノードを配置し、これをルートとします。
[Iterate] ノードがループ処理を行うノードで、このノードの [Iterations] パラメータで指定した回数だけ [Quadrant] ノードが実行されます。
[Iterate] ノードを複数繋げて多重ループも実現できるのですが、繰り返し回数を変数として取得できるのはその変数を使用したノードより手前直近の[Iterate]ノードのみです。
つまり、多重ループのそれぞれのループ回数は取得できません。
今回はそれでは困るので、1回のループで2重ループと同じ効果を出すようにします。
[Iterations] パラメータを空の関数とし、内部を以下のように作成します。

タイルのXYの整数を乗算して出力します。
例えばX=2、Y=2であれば4回ループとなります。タイル数分だけループするわけですね。
次に [Quadrant] ノードの処理を行います。
パラメータを変更するのは [Pattern] を [Input Image] に変更するだけです。
あとは各種パラメータの関数内部で処理を行うことにします。
まずはタイル上にパターンを配置しなければなりませんので、その処理を作成します。
[Branch Offset] のパラメータを関数化し、内部に入りましょう。
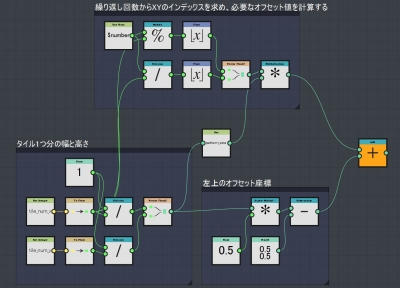
この関数は以下のように実装します。
(クリックで拡大)
ちょっと複雑でわかりにくいかもしれません。
まず左下のブロックはタイル1つ分の幅と高さを求めています。
タイルの分割数がXYともに2ならここで求められる値は(1/2, 1/2)=(0.5, 0.5)となります。
右下のブロックはパターンを左上ピッタリに配置する場合のオフセット値を求めています。
最後に上のブロックで繰り返し回数からXYのタイル座標を求め、それに見合った左上からのオフセット値を求めます。
これを右下のブロック(つまり左上のオフセット座標)に加算することで、繰り返し回数に依存したパターンのオフセット値を求めることが出来ます。
しかしこれだけでは大きなパターンが移動するだけです。サイズも適切なサイズに変更する必要があります。
この処理を [Pattern Size] パラメータ内に作成してもよいのですが、実はパターンサイズとして利用するパラメータは左下ブロックの結果と同等だったりします。
同じ計算を何度もやるのは面倒です。なので、この結果をローカル変数に設定します。
上の図の真ん中に [Set] ノードがあります。これは指定名(ここでは [pattern_size])のローカル変数を作成し、そこに値を格納しています。
この [Set] ノードで設定した値を使用するにはいくつかの条件が存在します。
1つ目の条件は、この値はこの関数を持ったパラメータが所属しているノード内でのみ有効です。
つまり、この場合は [Quadrant] ノードでのみ使用可能です。
使用する場合は [Get ~] ノードを使用しますが、同一関数内以外ではドロップダウンリストに表示されないのでて入力する必要があります。
2つ目の条件は [Set] ノードを利用したパラメータ以下のパラメータの関数内でしか使用できません。
今回の場合は [Branch Offset] 内部で使用しているため、この関数内部か、そこから下の [Quadrant] ノードのパラメータでしか利用できません。
つまり、[Color / Luminosity] パラメータの関数内では使用できないということです。
3つ目の条件としては [Set] ノードを有効にするには出力ノードとして設定したノードに対する処理の途中で挟む必要があるということです。
これについては後で説明します。
さて、ここで [pattern_size] というローカル変数にパターンサイズとして利用できる値が入力されましたので、[Pattern Size] パラメータの関数内でこれを使用しましょう。
[Pattern Size] パラメータを関数として、内部を以下のように設定します。

ここまで処理を作成すれば綺麗なタイル状に円が敷き詰められるはずです。
しかし、これからが本番。[Input Image 1] のイメージに従ってしきい値以上のグレーならパターンを表示するようにしましょう。
これを実現するにはタイル状に敷き詰められた各パターンの中心のピクセルを [Input Image 1] から取得し、この値がしきい値以上かどうかを確認、しきい値未満であれば [Pattern Size] を0にするという手法を取ります。
そのような加工をした結果が以下となります。

(クリックで拡大)
右上の部分がパターン中心のイメージのピクセルをサンプリングし、これがしきい値以上かどうかを調べている部分です。
しきい値以上であれば加工前の [pattern_size] 出力を選択し、しきい値未満であれば (0, 0) を選択します。
この選択結果を [pattern_size] に入力していますが、その後に [Sequence] ノードに繋げるようにしています。
なぜこのようにするのかというと、これまで通りに下部の加算部分を出力ノードとして選択してしまうと、その結果を求めるのに [pattern_size] への入力は通る必要がなく、SD内部で不要なノードとして無視されてしまうのです。
関数の出力には影響を与えないが処理されなければ困る、という今回のような場合には確実に処理が行われるようにするために [Sequence] ノードを使います。
このノードの入力ピンは上が [In]、下が [Last] となっていますが、出力されるのは [Last] ピンに入力された値です。
[In] に入力された値はこれ以降ではどこからも参照されませんが、処理だけは走ります。
これが [Set] ノードを使う条件の3つ目の回避方法です。活用していきましょう。
このようにノードを組み、[gray_threshold] を 0.5 に設定すると、三角形の形状で円が表示されるはずです。
円の数が少ないようでしたら [tile_num_x/y] の値を大きくしてあげましょう。
タイルの数がXYともに16の場合は以下のような結果となります。

最後に注意点を。
[Quadrant] ノードの [Pattern] はパラメータの関数化も出来ますし、関数内部で固定値 0 を出力すると [No Pattern] を選択されたように表示が消え、1 を出力すると [Input Image] が選択された状態となり円が表示されます。
パターンの表示/非表示はこちらでやるべきではないのか?
そう考えて [Pattern Size] を0にする方法でなく、[No Pattern] を利用した形で表示/非表示を切り替えられるようにしてみました。
しかし残念なことにこれはうまくいきませんでした。
なぜそうなっているのかはわからないのですが、どうやら [Pattern] の関数に対してはイメージのサンプリングが出来ないようです。
何か見落としてうまくいっていないだけなのかもしれませんが、私が試した際にはうまくいきませんでした。
注意しましょう。

























